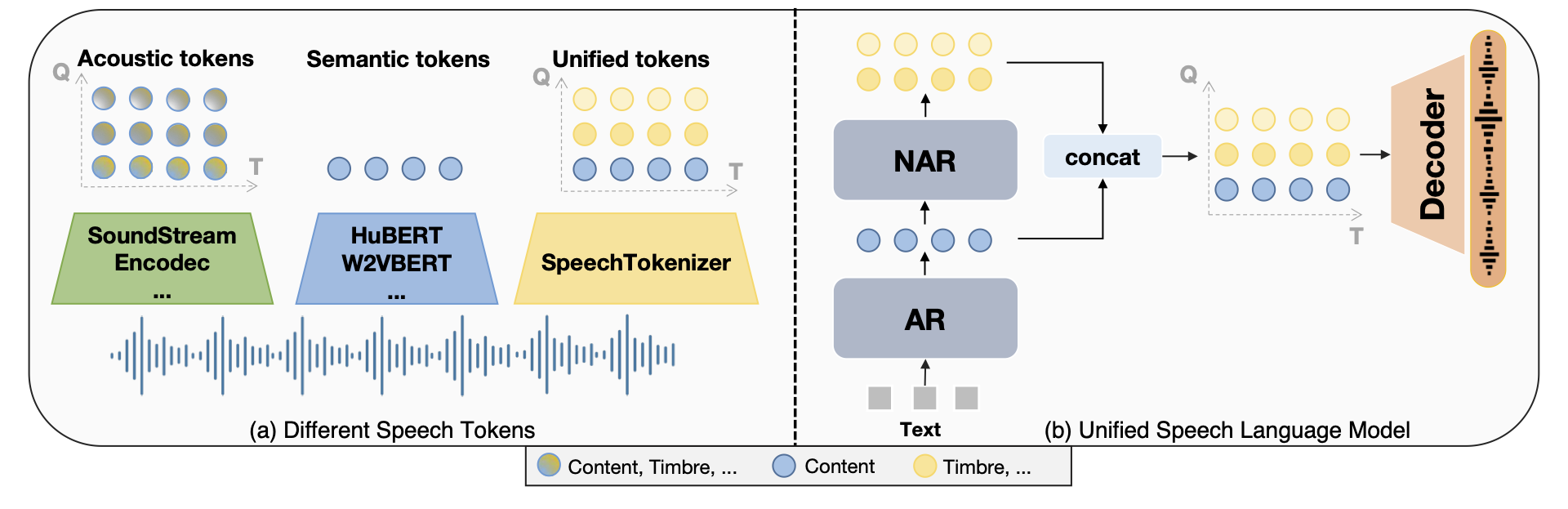
Current speech large language models build upon discrete speech representations,
which can be categorized into semantic tokens and acoustic tokens. However, existing speech tokens are not specifically designed for speech language modeling. We
establish SLMTokBench, a benchmark designed to assess the suitability of speech
tokens for building speech language models. Our results indicate that neither semantic nor acoustic tokens are ideal for this purpose. We propose SpeechTokenizer,
a unified speech tokenizer for speech large language models. SpeechTokenizer adopts the Encoder-Decoder architecture with residual vector quantization (RVQ).
Unifying semantic and acoustic tokens, SpeechTokenizer disentangles different aspects of speech information hierarchically across different RVQ layers. Leveraging
SpeechTokenizer, we construct a Unified Speech Language Model (USLM). Experimental results show that SpeechTokenizer performs comparably to EnCodec in
speech reconstruction and demonstrates strong performance on the SLMTokBench
benchmark. The USLM outperforms VALL-E in zero-shot Text-to-Speech tasks.
Speech Reconstruction:
Tokenizer
Raw
RVQ-1
RVQ-2:8
RVQ-1:8
EnCodec
SpeechTokenizer
EnCodec
SpeechTokenizer
EnCodec
SpeechTokenizer
Zero-shot Text-to-Speech:
Text
Speaker Prompt
GroundTruth
Vall-E
USLM
USLM(soundstorm)
She also defended the lord chancellors existing powers.
I can confirm that miss deacon has received a threatening phone call.
Ms.Anderson yesterday put a brave face on the departure.
To the hebrews it was a token that there would be no more universal floods.
The greeks used to imagine that it was a sign from the gods to foretell war or heavy rain.